오늘의 코딩순서 + 코딩 포인트
1. PACKAGE 패키지
1. 정의와 장점
- 자주 사용하는 프로그램과 로직을 모듈화
- 응용 프로그램을 쉽게 개발할 수 있음
- 프로그램의 처리 흐름을 노출하지 않아 보안 기능이 좋음
- 프로그램에 대한 유지 보수 작업이 편리함
- 같음 이름이 프로시저와 함수를 여러 개 생성할 수 있음
- 성능이 우수함
2. 실행
- 특정 사용자가 생성한 패키지 내의 프로시저를 호출
EXECUTE [패키지 명].[프로시저 명]- 다른 사용자가 생성한 패키지 내의 프로시저를 호출하는 방법
EXECUTE [사용자 ID].[패키지 명].[프로시저 명]
3. 역할
1. Header 역할 : 선언 (Interface 역할): 여러 PROCEDURE 선언 가능, 정의만 함
CREATE OR REPLACE PACKAGE emp_info AS
PROCEDURE all_emp_info;
END emp_info; --END 뒤에 프로시저나 패키지의 이름은 안 넣어도 되지만, 가독성을 위해 넣어주는 편
2.Body 역할 : 실제 구현
문제1-1) 모든 사원의 사원 정보(사번, 이름, 입사일)
-- 1. CURSOR : emp_cursor
-- 2. FOR IN
-- 3. DBMS -> 각각 줄 바꾸어 사번,이름,입사일
-- 4. 기본적 EXCEPTION 처리
CREATE OR REPLACE PACKAGE BODY emp_info AS
PROCEDURE all_emp_info -- 모든 사원의 사원 정보
IS
CURSOR emp_cursor
IS
SELECT empno , ename , to_char(hiredate, 'YYYY/MM/DD')hiredate
FROM emp
-- 모든 사원의 사원정보를 원하는 것이므로, 위의 parameter도 WHERE 조건문도 필요없음
ORDER BY hiredate;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR emp IN emp_cursor LOOP
DBMS_OUTPUT.PUT_LINE('사번 : '||emp.empno);
DBMS_OUTPUT.PUT_LINE('성명 : '||emp.ename);
DBMS_OUTPUT.PUT_LINE('입사일 : '||emp.hiredate);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM||'에러 발생');
END all_emp_info;
END EMP_info;
문제 1-2) 모든 사원의 부서별 급여 정보
-- 1. CURSOR : empdept_cursor
-- 2. FOR IN
-- 3. DBMS -> 각각 줄 바꾸어 부서명 ,전체급여평균 , 최대급여금액 , 최소급여금액
CREATE OR REPLACE PACKAGE emp_info AS
PROCEDURE all_emp_info; --모든 사원의 사원정보
PROCEDURE all_sal_info; -- 추가 문제 1-2) 부서별 급여 정보
END emp_info;PROCEDURE all_sal_info
IS
CURSOR empdept_cursor
IS
SELECT d.dname dname , round(avg(e.sal),3) avg_sal , MAX(e.sal) max_sal , MIN(e.sal) min_sal
FROM emp e , dept d
WHERE e.deptno = d.deptno
GROUP BY d.dname
;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR empdept IN empdept_cursor LOOP
DBMS_OUTPUT.PUT_LINE('부서명 : '||empdept.dname);
DBMS_OUTPUT.PUT_LINE('전체급여평균 : '||empdept.avg_sal);
DBMS_OUTPUT.PUT_LINE('최대급여금액 : '||empdept.max_sal);
DBMS_OUTPUT.PUT_LINE('최소급여금액 : '||empdept.min_sal);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM||'에러 발생');
END all_sal_info;
END EMP_info;
문제 1-3) 특정 부서의 사원 정보=> 사번, 성명, 입사일
CREATE OR REPLACE PACKAGE emp_info AS
PROCEDURE all_emp_info; --모든 사원의 사원정보
PROCEDURE all_sal_info; -- 추가 문제 1-2) 부서별 급여 정보
PROCEDURE dept_emp_info (p_deptno IN number); -- 추가 문제 1-3) 특정 부서의 사원 정보, 사번, 성명, 입사일
END emp_info PROCEDURE dept_emp_info
(p_deptno IN NUMBER)
IS
CURSOR emp_cursor
IS
SELECT empno , ename , to_char(hiredate,'YYYY/MM/DD') hiredate
FROM emp
WHERE deptno = p_deptno
ORDER BY hiredate
;
BEGIN
DBMS_OUTPUT.ENABLE;
FOR aa IN emp_cursor LOOP
DBMS_OUTPUT.PUT_LINE('사번 : '||aa.empno);
DBMS_OUTPUT.PUT_LINE('성명 : '||aa.ename);
DBMS_OUTPUT.PUT_LINE('입사일 : '||aa.hiredate);
END LOOP;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM||'에러 발생');
END dept_emp_info;
-----------------------------------------------------------------
END EMP_info;2. 데이터 모델링
1.정의
: 정보화 시스템을 구축하기 위해 어떤 데이터가 존재하는지 또는 업무가 필요로 하는 정보는 무엇인지를 분석하는 방법
2.키워드⭐⭐⭐
- 개념적 모델링: 업무중심적, 포괄적 수준의 모델링으로 추상화 수준이 높음, 전사적 데이터 모델링, EA 수립 시 많이 사용, 추상적임
- 논리적모델링: 시스템으로 구축하고자 하는 업무에 대해Key, 속성, 관계 등을 정확하게 표현, 재사용성이 높음
- 물리적 모델링: 실제로 데이터베이스에 이식할 수 있도록 성능 및 물리적인 성격을 고려하여 설계, 구체적임
- ERD
- 모델링 절차
3. 데이터 모델링의 필요성
| 구분 | 설명 |
| 최적화 시스템 구현 | 분석/설계 단계의 시스템 구현 구조 모델링을 통한 잠재적 위험요소에 대한 조기 발견 및 해결 방안 제시 |
| 유연한 시스템 | 프로세스 업무 변화에 대한 변동 사항이 적어 유연한 시스템 제공 가능 |
| 표준화 | 용어, 방법, 처리 절차 등의 문서 표준화 |
| 의사 소통 수단 | 표준화를 통한 사용자/설계자/개발자간 효율적인 의사 소통 수단 제공 |
| 시스템 적시성 확보 | 주요 설계 사항의 추후 변경에 따른 사업수행 지연 방지 |
| 효율적 시스템 구현, 방안 제시 |
DBMS 구축에 필요한 제반 기술들의 효율적인 적용을 위한 방안 제시 |
| 성능 품질 보증 | 분석, 설계시 성능의 관점에서 데이터 모델링과 업무 프로세스간의 상관관계를 파악하고 검증하여 성능에 대한 품질 보증 강화 |
| 요구사항 명세화 |
4. 수행절차
| 절차 | 주요내용 | 산출물 |
| 요구사항 분석 | - 기업 비즈니스를 이해하고 구조화하기 위한 정보를 정의 - 인터뷰 및 장표 분석을 통하여 요구사항을 도출, 정의, 명세, 검증 수행함 |
요구사항 분석서 |
| 개념적 모델링 | - 실세계의 정보 구조의 모형을 변환하여 일반화 시키는 단계 - 핵심 엔터티와 그들간의 관계를 표현하기 위해 ERD를 작성 - 사용자와 시스템 개발자가 데이터 요구 사항을 발견하는 것을 지원하며 의사소통의 기반을 마련함 - 현 시스템이 어떻게 변경되어야 하는가를 이해하는데 유용함 |
개념적 ERD |
| 논리적 모델링 | - 개념적 설계에서 추출된 실체와 속성들의 관계를 구조적으로 설계하는 단계 - 정확한 업무 분석을 통한 자료의 흐름을 분석하여 실체와 속성들의 관계를 구조적으로 설계 - 논리적 데이터베이스 모델링 단계에서 완벽한 정규화 과정을 수행 - 식별자 확정, 정규화 , M:M 관계 해소, 참조 무결성 규칙 정의 등을 수행 |
논리 데이터 모델 |
| 물리적 모델링 | - 정규화된 논리적 데이터모델을 개발, DBMS의 특성에 적합하도록 효율적인 데이터베이스 스키마를 구축하는 단계 - Data의 DISK상의 위치, 인덱스, 파티션테이블, 분산 설계 등을 수행 - 성능을 고려한 반정규화 실시 |
물리 데이터 모델 |
3.정규화 Normalization ⭐⭐⭐(기사시험 단골문제)
1.정의
- 관계형 데이터 모델에서 데이터의 중복성을 제거하여 이상 현상을 방지하고 데이터의 일관성과 정확성을 유지하기 위한 과정
- 속성(Attribute)들 간의 종속성(Dependency)을 분석하여 기본적으로 하나의 종속 성이 하나의 Relation으로 표현되도록 분해해 나가는 과정
- 이상 현상(Anomaly)을 야기하는 Attribute 간의 종속 관계를 제거하기 위해 Relation을 작은 Relation으로 무손실 분해하는 과정
2. 정규화의 필요성
- 중복의 제거로 저장 공간의 최소화
- 종속성 삭제로 일관성 및 무결성 보장
- 자료의 삽입, 갱신 및 삭제에 따른 이상현상(Anomaly) 제거
- 데이터 신규 발생시 DB 재구성의 필요성을 감소(유연한 구조)
- 연관관계 이용한 관리 및 이해 편리
3. ⭐정규화의 원칙
- 정보의 무손실: 분해된 Relation이 표현하는 정보는 분해되기 전의 정보를 모두 포함하고 있어야 하며, 보다 더 바람직한 구조여야 함
- 데이터 중복성 감소: 중복으로 인한 이상 현상의 제거
- 분리의 원칙: 하나의 독립된 관계성은 하나의 독립된 Relation으로 분리하여 표현
4. 이상현상
1. 정의: 데이터의 중복으로 릴레이션을 처리할 때 즉, 데이터를 변경하려고 할 때 이상현상(Anomaly)이 발생
2. 원인
- 여러 가지 종류의 사실들을 하나의 릴레이션 표현할 때 발생함
- 속성들간에 존재하는 여러 가지 종속 관계에 대해 정규화가 실행되지 않았기 때문
3. 종류⭐⭐⭐⭐⭐
- 삭제 이상: 한 튜플을 삭제함으로써 유지해야 할 정보까지 삭제되는 연쇄삭제(triggered deletion) 현상이 일어나게 되어 정보손 실이 발생하게 되는 현상
- 삽입 이상: 어떤 데이터를 삽입하려고 할 때 불필요하고 원하지 않는 데이터도 함께 삽입해야 하고 그렇지 않으면 삽입이 되지 않는 현상
- 갱신 이상: 중복된 튜플 중 일부 튜플의 어트리뷰트 값만을 갱신하여 정보의 모순성이 생기는 현상
5. 함수적 종속성

1. 정의
- 데이터들이 어떤 기준 값에 의해 종속되는 현상을 지칭
- 기준 값은 결정자(determinant), 종속되는 값은 종속자/의존자 (dependent)
- 부분 함수 종속성(partial functional dependency)은 한 개 또는 그 이상의 속성이 Primary key(PK) 의 일부분에 함수적으로 종속하는 것
2. 예시

- 이름, 주소, 성별은 주민등록 번호 속성에 종속됨
- 표기법: 주민등록번호 [이름, 주소, 성별]
3.유형
- 함수적 종속성 (Functional Dependency)
- 하나의 속성(X)이 다른 속성(Y)을 결정지을 때 Y는 X에 함수적 으로 종속되어 있다고 표현
- 완전함수종속, 부분함수종속, 이행함수종속
- 적용 사례: 1NF, 2NF, 3NF, BCNF
- 다중값 종속성 (Multivalued Dependency)
- 한 Relation에 둘 이상의 독립적인 다중값 속성이 존재하는 경우 이를 1NF로 전환하면 다중값 종속 발생
- 두 개의 독립적인 다중값 속성을 서로 다른 두 개의 Relation 으로 분리
- 적용 사례: 4NF
- 결합 종속성 (Join Dependency)
- 둘로 나눌 때는 원래의 관계로 회복할 수 없으니 셋 또는 그 이상으로 분리시킬 때는 원래의 관계로 회복할 수 있는 경우
- 적용 사례: 5NF
4. ⭐⭐⭐함수종속도 (암스트롱의 함수종속규칙)
#1. 암스트롱의 추론 규칙들
1. (반사 규칙) : 부분집합(⊆, ⊇)의 성질(Subset Property)
Y ⊆ X이면, X → Y이다. => 이를 '재귀법칙'이라고 함
2. (첨가(Augmentation) 규칙) : 증가
X → Y이면, XZ → YZ이다. (표기: XZ는 X∪Z를 의미)
3. (이행(Transitivity) 규칙) : X → Y이고 Y → Z이면, X → Z이다.
- A1, A2, A3는 Sound하고 Complete 추론 규칙 집합을 형성한다
- 건전성 특성: A1, A2, A3로부터 유도된 모든 함수적 종속성은 모든 릴레이션 상태에 대해 성립함
#2. 추가적으로 유용한 추론 규칙들
4 : (분해(Decomposition) 규칙) : X → YZ이면, X → Y이고 X → Z이다.
5 : (결합(Union) 규칙) : 연합 X → Y이고 X → Z이면, X → YZ이다.
6 : (의사이행(Pseudotransivity) 규칙) : 가이행 X → Y이고 WY → Z이면, WX → Z이다.
- 완전성 특성: 위의 세 규칙 뿐 아니라 다른 추론 규칙들도 A1, A2, A3만으로부터 추론 가능하다
6. 정규화의 절차 및 유형
1.정규화의 절차: 데이터들의 함수의 종속성을 이용하여 데이터 모델링을 최적화하는 과정을 의미함

2.정규화의 유형
| 구분 | 단계 | 내용 | 특성 |
| 기초적정규화 | 1차 정규화 (1NF) |
- 반복되는 속성 제거 - Relation R에 속한 모든 도메인이 원자값(atomic value)만으로 되어있는 경우 |
데이터간 중복성이 강함 ↓ ↑ 데이터간 결합성이 강함 |
| 2차 정규화 (2NF) |
- 부분함수 종속성 제거 - Relation R이 1NF이고 Relation의 기본 키가 아닌 속성들이 기본 키에 완전히 함수적으로 종속할 경우 |
||
| 3차 정규화 (3NF) |
- 이행함수 종속성 제거 - Relation R이 2NF이고 기본 키가 아닌 모든 속성들이 기본 키에 대하여 이행적 함수 종속성(Transitive FD)의 관계를 가지지 않는 경우, 즉 기본 기 외의 속성들간에 함수적 종속적을 가지지 않는 경우 |
||
| BCNF (Boyce/Codd NF) |
- 결정자함수 종속성 제거 - Relation R의 모든 결정자가 후보 키일 경우 |
||
| 진보적 정규화 | 4차 정규화 (4NF) |
- 다중값 종속성 제거 - BCNF를 만족시키면서 다중값 종속을 포함하지 않는 경우 |
|
| 5차 정규화 (5NF) |
- 결함 종속성 제거 - 4NF를 만족시키면서 후보키를 통해서만 조인 종속이 성립되는 경우 |
3. 반정규화
정의: 정규화된 엔티티 타입, 속성, 관계에 대해 시스템의 성능향상과 개발과 윤영의 단순화를 위해 데이터모델을 통합하는 프로세스
기준: 정합성 ↔ 성능 데이터 무결성 ↔ 테이블 단순화
절차
| 순서 | 절차 | 설명 |
| 1 | 반정규화 대상 조사 | - 범위 처리 빈도수 조사 - 대량의 범위 처리 조사 - 통계성 프로세스 조사 - 테이블 조인 개수 |
| 2 | 다른 방법 유도 검토 | - 뷰(VIEW) 테이블 - 클러스터링 적용 - 인덱스의 조정 - 응용 어플리케이션 |
| 3 | 반정규화 적용 | - 테이블 반정규화 - 속성의 반정규화 - 관계의 반정규화 |
4. 반정규화 방법
| 순서 | 방법 | 설명 |
| 1 | 테이블 병합 | - 1:1 관계의 테이블 병합 - 1:M 관계의 테이블 병합 - 수퍼타입 서브타입 테이블 병합 |
| 2 | 테이블 분할 | - 수직 분할 - 수평분할 |
| 3 | 테이블 추가 | - 중복 테이블 추가 - 통계 테이블 추가 - 이력 테이블 추가 - 부분 테이블 추가 |
⭐⭐⭐(면접문제)강연결과 약연결을 설명해보시오
: 강연결은 Primary키일 때 강연결, 둘 중 하나가 일반 함수속성일때(이행함수 종속성일때) 연결하면 약연결
문제 3-1)


>>내가 푼 것

1차 정규화 2차 정규화 3차 정규화
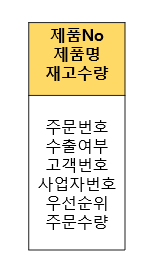


>> 선생님의 답

1차 정규화 2차 정규화 3차 정규화



4. 배치(Batch)성 프로그램
정의: 사용자와 상호작용 없이 대량의 데이터를 처리하는 여러 작업들을 하나로 묶어 일괄로 수행되도록 하는 것을 말함


수업교재
419 423 428 429 430 431 433 435 438 440 441
447 453
461 463 464 465 471 475 476
481 482 483 485 487 495 500 502 504 508 509
오늘의 숙제
'DB > Oracle' 카테고리의 다른 글
| 2024_09_02_월 (0) | 2024.09.02 |
|---|---|
| 2024_07_08_월 DB(ORACLE) 시험 (0) | 2024.07.08 |
| 2024_07_03_수~ 07_04_목 (0) | 2024.07.03 |
| 2024_07_02_화 (0) | 2024.07.02 |
| 2024_07_01_월 (0) | 2024.07.01 |



